
Serbestlik Derecesi: Tanımı, Hesaplanması ve İstatistiksel Testlerdeki Rolü
- Nominal Analiz
- 6 Ara 2025
- 4 dakikada okunur

📌 Serbestlik Derecesinin Temel Tanımı
Serbestlik derecesi, istatistiksel bir değeri hesaplarken kullanılan bağımsız bilgi parçacıklarının sayısını ifade eder. Genellikle v veya df ile gösterilir ve temel formülü şöyledir:
df = örneklem büyüklüğü − kısıtlama sayısı
Bu kavram, istatistiksel bir testin sonuçlarının değerlendirilmesinde kritik öneme sahiptir. Serbestlik dereceleri, test istatistiğinin yanında parantez içinde raporlanır ve kullanılan dağılımın şeklini belirler.
Örnek
10 kişilik bir örneklem üzerinde yapılan bir one-sample t test için:
n = 10
df = 10 − 1 = 9
Elde edilen t değeri 1.41 ve p değeri 0.19 ise sonuç şu şekilde raporlanır:t(9) = 1.41, p = 0.19

🔍 Serbestlik Derecesi Neden Önemlidir?
İstatistiksel bir tahmin yapılırken örnekleme ait değerler arasında belirli kısıtlamalar bulunur. Bu kısıtlamalar nedeniyle tüm değerler serbestçe değişemez. Serbestlik derecesi, yalnızca gerçekten bağımsız olarak değişebilen değerlerin sayısını gösterir.
Genel gözlem:
Küçük örneklem: Daha az bağımsız bilgi → düşük df
Büyük örneklem: Daha fazla bağımsız bilgi → yüksek df
Not: Serbestlik derecesi, örneklem büyüklüğüyle ilişkili olsa da aynı şey değildir; daima örneklemden daha küçüktür.
🍰 Serbestçe Değişebilme: Tatlı Analojisi
Bu analoji, bir değerin serbestçe değişebilmesinin ne anlama geldiğini açıkça gösterir.
Bir öğrenci, yemekhane menüsündeki 7 farklı tatlıdan hafta boyunca her gün farklı bir tatlı seçmek ister.
Bu durum bir kısıtlama oluşturur.
Pazartesi: 7 seçenek
Salı: 6 seçenek
Çarşamba: 5 seçenek …
Pazar gününe gelindiğinde sadece 1 seçenek kalır; yani bu gün serbestçe değiştirilemez.
Bu durumda:
6 gün serbestçe değişebilir,
1 gün kısıtlanmıştır.
Serbestlik derecesinin doğası tam olarak budur:
Bazı seçimler bağımsızdır, son seçim ise önceki seçimlere bağlı hâle gelir.

🔢 Serbestçe Değişebilme: Toplam Örneği
Bu örnek, sayısal bir kısıtlamanın serbestlik derecelerini nasıl etkilediğini açıkça gösterir.
“Toplamı 100 olacak şekilde 5 tamsayı seç” dediğimizde şu olur:
İlk dört sayıyı serbestçe seçebilirsin.
Ancak beşinci sayı kısıtlıdır; çünkü toplamın 100 olması zorunludur.
Örneğin seçtiğin ilk dört sayı:
15, 27, 42, 3 → toplam 87
5. sayının 13 olması zorunludur.
Bu durumda:
4 sayı serbestçe değişebilir → df = 4
Son değer kısıtlıdır.
📊 Serbestlik Derecesi ve Hipotez Testleri
Serbestlik derecesi, hipotez testlerinin kritik değerini belirleyen ana unsurlardan biridir.
Test istatistiği, ilgili dağılımın df değerine göre yorumlanır.
Serbestlik Derecesinin Dağılıma Etkisi
Student’s t
Chi-square
Diğer test istatistikleri
hepsi df değerine göre farklı şekiller alır.
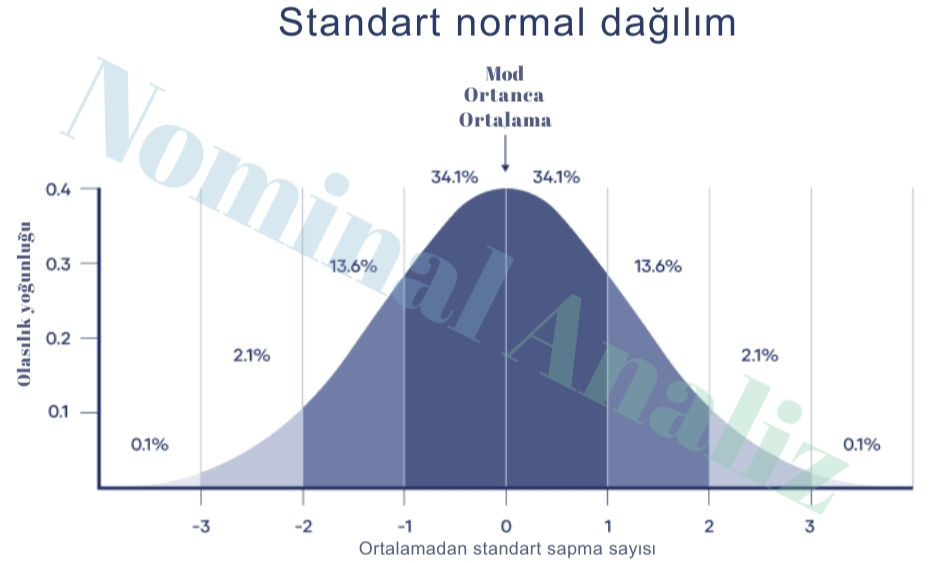
📈 Student’s t Dağılımında Serbestlik Derecesi
Bir t testinde t değeri hesaplandıktan sonra, kritik değer seçilirken t dağılımı kullanılır. Bu dağılım serbestlik derecesine göre değişir:
df = 1: Dağılım çok daha sivri ve uç değer olasılığı yüksektir (leptokurtiktir).
df arttıkça: Dağılım daralır ve normale yaklaşır.
df ≥ 30: t dağılımı neredeyse normal dağılımla aynıdır.
Bu değişim, örneklem büyüdükçe tahminin daha kesin hâle gelmesiyle ilgilidir.
Örnek
10 kişilik örneklem → sample mean = 820 mg
Son kişi örneklemin ortalaması 820 olacak şekilde belirlenir.
Bu nedenle:
Yalnızca 9 değer serbestçe değişebilir → df = 9
Bu df, t dağılımından kritik değer bulmak için kullanılır.
🟨 Chi-square Dağılımında Serbestlik Derecesi
Chi-square dağılımı, Student’s t dağılımından farklı bir şekilde df’e göre değişir:
df < 3: Dağılım ters “J” biçimindedir.
df ≥ 3: Sağ çarpık, tepe noktası Χ² = df − 2 olan bir yapı oluşur.
df > 90: Normal dağılıma çok benzer.
Serbestlik derecesi arttıkça chi-square dağılımı daha simetrik görünür.
🧮 Serbestlik Derecesi Nasıl Hesaplanır?
Genel formül:
df = n − r
Burada:
n: Örneklem büyüklüğü
r: Kısıtlama (tahmin edilen parametre) sayısı
df negatif olamaz; bu nedenle tahmin edilen parametre sayısı her zaman örneklemden küçük olmalıdır.
📚 Testlere Özel Serbestlik Dereceleri Formülleri
Aşağıdaki tabloda yaygın testlerin df formülleri verilmiştir.
Test | Formül | Açıklama |
One-sample t test | df = n − 1 | — |
Independent samples t test | df = n₁ + n₂ − 2 | n₁: grup 1 örneklem sayısı, n₂: grup 2 örneklem sayısı |
Dependent samples t test | df = n − 1 | n: çift sayısı |
Simple linear regression | df = n − 2 | — |
Chi-square goodness of fit test | df = k − 1 | k: grup sayısı |
Chi-square test of independence | df = (r − 1) × (c − 1) | r: satır sayısı, c: sütun sayısı |
One-way ANOVA | Between-group df = k − 1 Within-group df = N − k Total df = N − 1 | k: grup sayısı, N: tüm grupların toplam örneklem sayısı |
Serbestlik Derecesi Sıkça Sorulan Sorular (SSS)
Serbestlik derecesi arttıkça Student’ın t dağılımının şekli nasıl değişir?
Serbestlik derecesi arttıkça Student’ın t dağılımı daha az leptokurtik hâle gelir.Bu değişimin temel etkileri:
Uç değer olasılığı azalır.
Dağılım giderek standart normal dağılıma benzemeye başlar.
Yani df arttıkça t dağılımı daha simetrik ve daha az yayvan bir forma dönüşür.
Serbestlik derecesi arttıkça ki-kare dağılımının şekli nasıl değişir?
Ki-kare dağılımı, serbestlik derecesine göre oldukça belirgin şekilde değişir:
df = 1 veya 2 iken: Dağılım ters “J” biçimindedir.
df ≥ 3 olduğunda: Sağ çarpık bir tepe (hump) oluşur.
df arttıkça:
Sağ çarpıklık azalır,
Tepe noktası sağa doğru kayar,
Dağılım normal dağılıma giderek daha çok benzer hâle gelir.
Bir hipotez t’nin kritik değerini kullanarak nasıl test edilir?
Hipotez testi, kritik değer yaklaşımıyla şu adımlarla gerçekleştirilir:
Örneklem için t değerini hesapla.
t tablosundan uygun serbestlik derecesine göre kritik t değerini bul.
Hesaplanan t değerinin mutlak değerini kritik t değeriyle karşılaştır.
Eğer |t| kritik değerden büyükse, yokluk hipotezini reddet.
Eğer |t| kritik değerden küçükse, yokluk hipotezini reddetme.
Bu dört adım, t-testi sonuçlarının kritik değer üzerinden yorumlanmasını sağlar.


Yorumlar