
Ordinal Regresyonda Options (Ayarlar) Menüsü Ayarlarının Mantığı ve Uygulama Stratejisi
- Nominal Analiz
- 6 Ara 2025
- 3 dakikada okunur

Ordinal regresyon analizi, kategorik ve sıralı bir bağımlı değişkenin bir veya daha fazla bağımsız değişkenle olan ilişkisini modellemek için kullanılan güçlü bir yöntemdir. Ancak yöntemin doğru çalışabilmesi, parametrik tahmin sürecini yöneten “Options” ayarlarının doğru anlaşılmasıyla mümkündür.
Bu bölüm, SPSS'in sunduğu ayarların ne anlama geldiğini, hangi durumlarda değiştirilebileceğini ve araştırmacının analize nasıl yön vermesi gerektiğini açıklamaktadır.
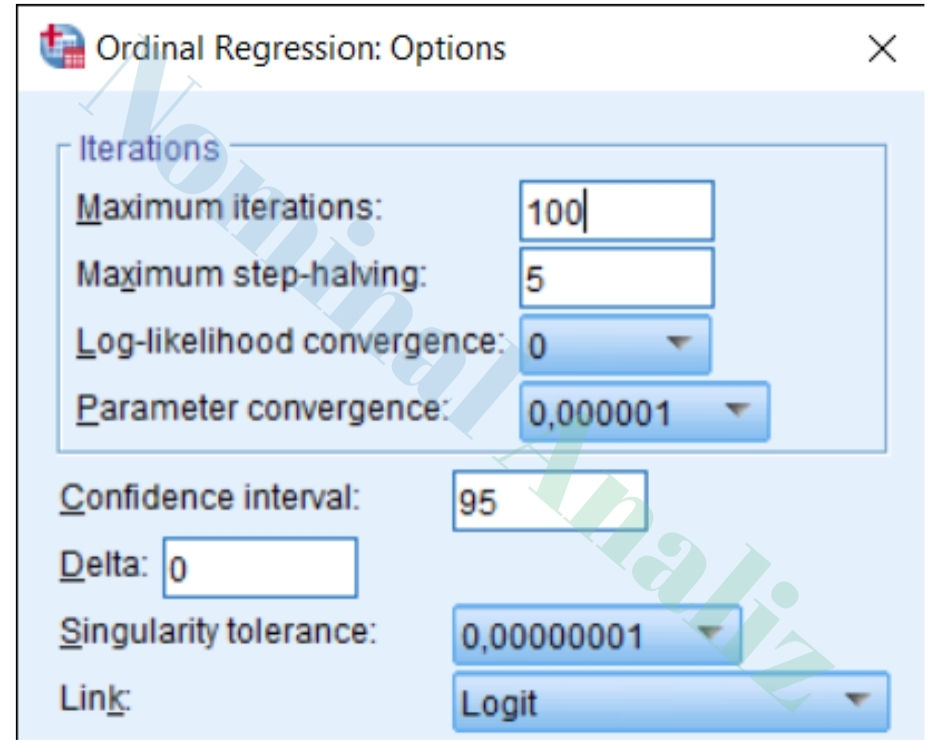
İteratif Tahmin Algoritmasının Kontrolü
Ordinal regresyon, maksimum olabilirlik tahminine (Maximum Likelihood Estimation – MLE) dayalı iteratif bir optimizasyon süreci ile çalışır. SPSS bu süreci varsayılan ayarlarla yönetir; ancak yazılım, istenildiğinde algoritmanın daha hassas veya daha gevşek çalışmasına da izin verir.
Maksimum Iterasyon Sayısı
Tahmin sürecinde modelin kaç deneme sonrası duracağını belirler.
Çok karmaşık modellerde varsayılan sayı yetmeyebilir; model yakınsamayı sağlayamazsa bu değerin artırılması önerilir.
Çok küçük bir değer verilmesi, modelin erken durmasına yol açar ve sonuçlar güvenilir olmayabilir.
Maximum Step-Halving
Model bir adımda kararsızlık yaşarsa, adım büyüklüğü yarıya bölünerek daha temkinli ilerlenir.
Yüksek değerler, algoritmanın deneme kapasitesini artırır; düşük değerler süreci hızlandırır ama stabiliteyi zayıflatabilir.
Log-Likelihood Convergence (Yakınsama Ölçütü)
Modelin log-olabilirlik değerindeki değişim belirli bir eşik altına düştüğünde tahmin süreci durur.
Değer ne kadar küçükse, model o kadar hassas çalışır.
Çok küçük bir eşik hesaplama süresini artırabilir; çok büyük bir eşik ise erken durmaya yol açabilir.
Parameter Convergence
Parametre tahminlerinde değişim belirlenen eşik altına düştüğünde algoritma tamamlanır.
Çok kategorili bağımlı değişkenlerde bu kriter, log-likelihood’a göre daha kritik bir rol oynayabilir.
Bu dört ayar çoğu analizde varsayılan değerleriyle yeterlidir. Değişiklik yalnızca model yakınsamıyorsa gereklidir.
Güven Aralığı Seviyesi
Modeldeki parametre tahminleri için güven aralığı yüzdesi bu bölümde belirlenir.
Varsayılan: %95
Daha dar güven aralığı isteniyorsa değer yükseltilebilir.
Klinik, farmakolojik veya hassas ölçümlerin yer aldığı çalışmalarda genellikle %95 veya %99 tercih edilir.
Delta Ayarı (Sıfır Hücre Problemi İçin)
Bağımsız değişken kategorilerinin bazı kombinasyonlarında yeterli gözlem yoksa sıfır hücre sorunu ortaya çıkar. Delta değeri bu hücrelere küçük bir düzeltme ekleyerek hesaplamayı mümkün kılar.
Varsayılan olarak 0 kullanılabilir.
Çok küçük örneklemli ya da çok kategorili modellerde 0.01 – 0.05 gibi küçük delta değerleri çözüm sağlayabilir.
Singularity Tolerance (Tekillik Kontrolü)
Bazı bağımsız değişkenler birbirine yüksek düzeyde bağımlı olduğunda modelde tekillik problemi yaşanabilir. SPSS, singularity tolerance değeri yardımıyla bu gibi durumları tespit eder.
Daha yüksek tolerans → daha katı multikolineerlik kontrolü
Daha düşük tolerans → daha esnek bir modelleme
Genel kullanımda varsayılan değerler yeterlidir. Büyük veri setlerinde ise toleransı biraz artırmak modelin daha hızlı ve stabil çalışmasına yardımcı olabilir.
Link Fonksiyonunun Seçimi: Modelin En Kritik Kararı
Ordinal regresyonun en önemli özelliği, bağımlı değişkenin kategorik yapısını modellemek için bir “link fonksiyonu” kullanmasıdır. Bu fonksiyon, kategorilerin kümülatif olasılıklarını matematiksel olarak dönüştürür ve modelin karakterini belirler.

1. Logit Link Fonksiyonu
En yaygın kullanılan link türüdür.
Kategoriler dengeli dağıldığında uygun sonuç verir.
Klinik, sosyal bilim ve davranış araştırmalarında genellikle varsayılan tercihtir.
2. Complementary Log-Log (cloglog)
Yüksek kategori değerlerinin daha olası olduğu durumlarda ideal.
Örneğin tedaviye yanıtın artarak devam ettiği klinik ölçümlerde tercih edilebilir.
3. Negative Log-Log
Düşük kategorilerin daha olası olduğu durumlarda uygundur.
Örneğin risk düzeyi düşük bir toplumda “hastalık şiddeti” değişkeni düşük kategoride yoğunlaşabilir.
4. Probit
Latent (gizli) bir sürekli değişkenin normal dağıldığı varsayılır.
Psikometri, biyoistatistik ve davranış bilimlerinde sık kullanılır.
Logit’e benzer sonuç verir; ancak uç değerlerde daha duyarlıdır.
5. Cauchit
Dağılımın uç noktalarında aşırı değerlerin bulunduğu durumlarda kullanılır.
Çok uç vaka içeren klinik çalışmalarda tercih edilebilir.
Link fonksiyonunun seçimi, modele teorik bakışa göre yapılmalıdır; yalnızca istatistiksel uygunluk yeterli değildir.
Genel Değerlendirme
Options sekmesi, ordinal regresyonun algılayış biçimini doğrudan etkiler. Tahmin süreci, veri yapısı, kategori dağılımı ve model karmaşıklığı bu ayarlarla kontrol edilebilir. Çoğu araştırmada varsayılan seçenekler doğru sonuçlar verir; ancak yakınsama hataları, dengesiz kategori dağılımı veya yüksek çoklu bağlantı durumlarında parametrik ayarların değiştirilmesi gerekebilir.
Link fonksiyonu seçimi ise analizin kalbidir ve araştırmacının teorik beklentisiyle modelin matematiksel yapısını uyumlu hâle getirmesi gerekir.



Yorumlar