
Bağımlı Gruplarda T-Testi ile Uygulamalı SPSS Analizi: Egzersiz, Terapi, Eğitim ve Beslenme Müdahalelerinin 125 Kişilik Örneklem Üzerindeki Etkileri
- Nominal Analiz
- 23 Tem 2025
- 4 dakikada okunur

Güncelleme tarihi: 24 Tem 2025
Uygulamalı veri analizine başlamadan önce konuyu kısaca hatırlayalım.
Bağımlı Gruplarda T-Testi Nedir?
Bağımlı Gruplarda T-Testi (Paired Samples T-Test), aynı bireylerden iki farklı zamanda ya da iki farklı koşulda alınan ölçümler arasındaki ortalama farkın istatistiksel olarak anlamlı olup olmadığını test etmek için kullanılır.
Ne İşe Yarar?
Bu test sayesinde bir müdahale (örneğin eğitim, terapi, egzersiz) öncesi ve sonrası ölçümler karşılaştırılarak uygulamanın etkisi değerlendirilir.
Hangi Durumlarda Kullanılır?
Bağımlı gruplar t-testi şu durumlarda tercih edilir:
Aynı grubun iki farklı zamanda ölçülen sonuçları karşılaştırıldığında (örnek: eğitim öncesi-sonrası bilgi düzeyi),
Aynı bireylerin iki farklı koşuldaki performansı ölçüldüğünde (örnek: ilaçsız ve ilaçlı dönemlerde anksiyete düzeyi),
Eşleştirilmiş deneklerin sonuçları analiz edildiğinde (örnek: tedavi gören hasta ve yaşıt kontrol grubunun eşleştirilmiş skorları).
Aşağıdaki dosya indirme bağlantısından kullanılan veri setini indirebilir ve inceleyebilirsiniz.
Bu veri seti şunları içermektedir:
BMI_Before / BMI_After: Egzersiz öncesi ve sonrası Vücut Kitle İndeksi
Anxiety_Before / Anxiety_After: Terapi öncesi ve sonrası anksiyete skoru
Motivation_Before / Motivation_After: Eğitim öncesi ve sonrası motivasyon skoru
Glucose_Before / Glucose_After: Beslenme programı öncesi ve sonrası kan şekeri seviyesi
Her bir çifte ait veriler eşleştirilmiş olup SPSS’te Paired Samples T-Test (bağımlı gruplarda t-testi) uygulamaları için uygundur.
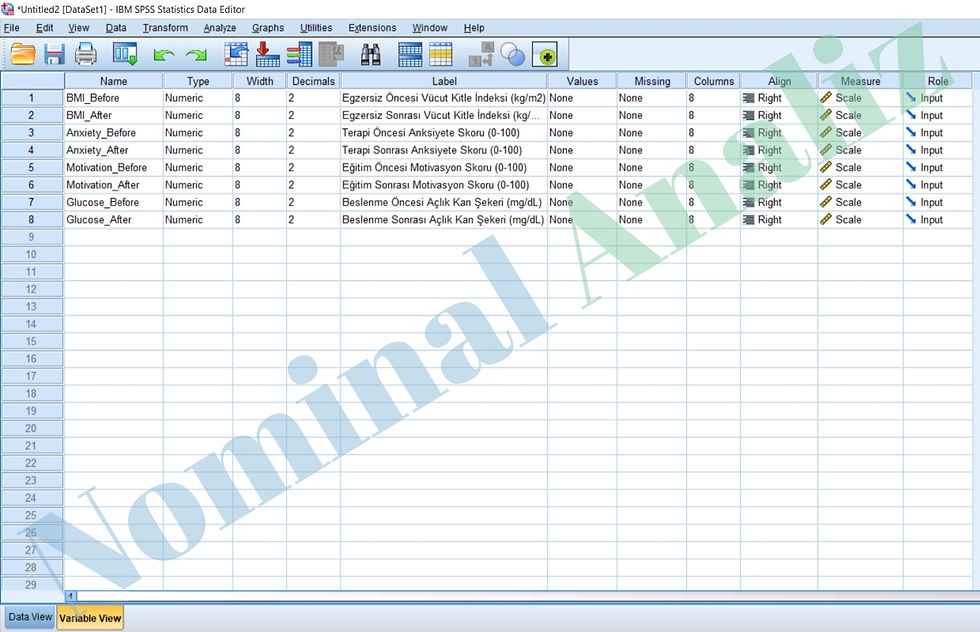
Aşağıda, SPSS “Variable View”’de yer alacak şekilde tüm sütunlar doldurulmuş haliyle değişken tanımlama tablosunu bulabilirsiniz:
Name | Type | Width | Decimals | Label | Values | Missing | Columns | Align | Measure | Role |
BMI_Before | Numeric | 8 | 2 | Egzersiz Öncesi Vücut Kitle İndeksi (kg/m²) | 8 | Right | Scale | Input | ||
BMI_After | Numeric | 8 | 2 | Egzersiz Sonrası Vücut Kitle İndeksi (kg/m²) | 8 | Right | Scale | Input | ||
Anxiety_Before | Numeric | 8 | 2 | Terapi Öncesi Anksiyete Skoru (0–100) | 8 | Right | Scale | Input | ||
Anxiety_After | Numeric | 8 | 2 | Terapi Sonrası Anksiyete Skoru (0–100) | 8 | Right | Scale | Input | ||
Motivation_Before | Numeric | 8 | 2 | Eğitim Öncesi Motivasyon Skoru (0–10) | 8 | Right | Scale | Input | ||
Motivation_After | Numeric | 8 | 2 | Eğitim Sonrası Motivasyon Skoru (0–10) | 8 | Right | Scale | Input | ||
Glucose_Before | Numeric | 8 | 2 | Beslenme Öncesi Açlık Kan Şekeri (mg/dL) | 8 | Right | Scale | Input | ||
Glucose_After | Numeric | 8 | 2 | Beslenme Sonrası Açlık Kan Şekeri (mg/dL) | 8 | Right | Scale | Input |
Aşağıdaki görsel ise veri setinin SPSS Variable View sekmesinde değişken tanımlamasına aittir.
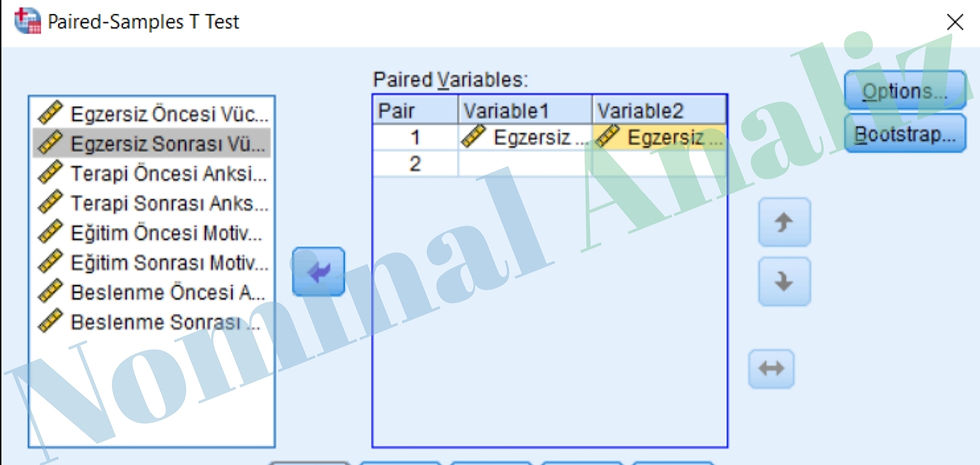
Şimdide SPSS yazılımında "Bağımlı Gruplar T Testi'nin nasıl gerçekleştiğini inceleyelim:
1- Analyze, Compare Means, Paired Samples T Test seçilir.
2- Paired Samples T Test penceresinde sol taraftaki değişkenler listesinden nicel değişkenler seçilerek sağ taraftaki Paired Variable(s) kutusuna –eşleştirilerek- aktarılır.
3- OK tıklanır.
Aşağıdaki görsel ise "Egzersiz Öncesi/Sonrası Vücut Kitle İndeksi (kg/m2) değişkenlerinin "Paired Variable(s)" kutusuna eklenmesine aittir.
Şimdi de SPSS çıktısında elde edilen tabloları aşama aşama yorumlayalım.
Tablo 1: Paired Samples Statistics
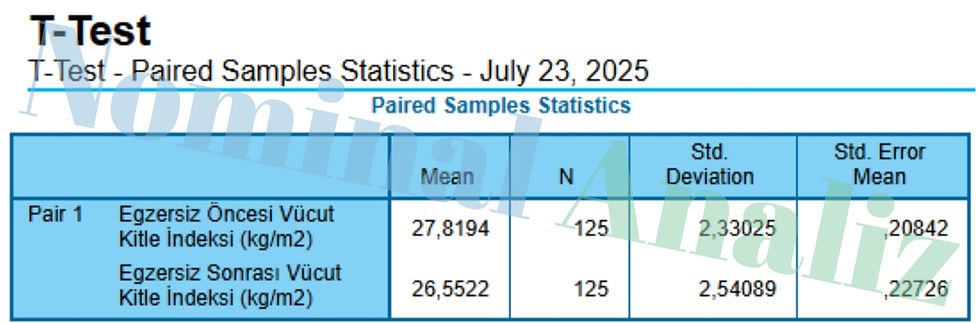
Amaç: Egzersiz öncesi ve sonrası Vücut Kitle İndeksi (VKI) ölçümlerinin temel özet istatistiklerini sunmak.
Açıklamalar:
Mean (Ortalama):
Egzersiz öncesi VKI ortalaması = 27,82
Egzersiz sonrası VKI ortalaması = 26,55Bu fark, egzersiz programı sonrasında katılımcıların ortalama VKI’sinde bir düşüş olduğunu gösteriyor.
N (Örneklem Büyüklüğü):
Her iki ölçümde de 125 katılımcı kullanıldı.
Paired Samples T Testinde, her katılımcının “önce” ve “sonra” ölçümü eşleştirildiği için her iki satırda da aynı N değeri görülür.
Std. Deviation (Standart Sapma):
Önce: 2,33 kg/m²
Sonra: 2,54 kg/m²Verilerin ortalamadan ne kadar saptığını, yani bireyler arasında VKI dağılımının ne kadar geniş olduğunu ölçer. Sonrası ölçümde biraz daha yüksek sapma var; egzersize yanıt bireyden bireye biraz daha farklılaşmış olabilir.
Std. Error Mean (Ortalamanın Standart Hatası):
Önce: 0,2084
Sonra: 0,2273Örneklem ortalamasının, gerçek popülasyon ortalamasını tahmin etme belirsizliğini gösterir. Örneklem büyüklüğü ve veri sapması birleşince ortalamanın ne kadar güvenilir olduğu hakkında fikir verir.
Tablo 2: Ölçümler Arası Korelasyon (Paired Samples Correlations)
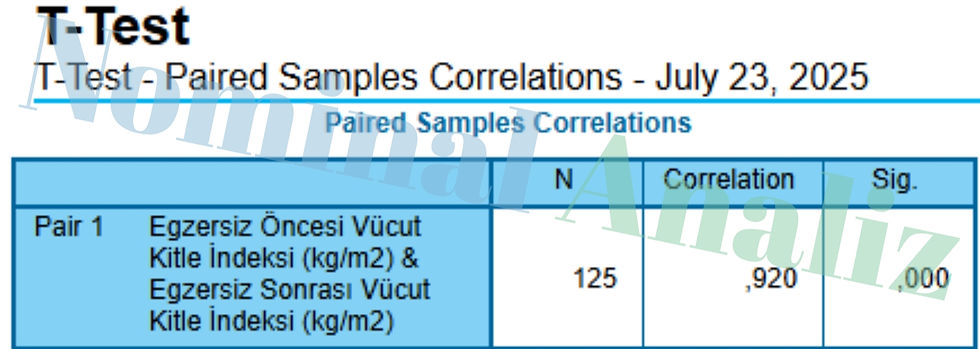
Ne Anlama Geliyor?
Correlation (r = 0,920)
Egzersiz öncesi ve sonrası VKİ ölçümleri arasında çok güçlü bir pozitif ilişki var.
Yani “düşük” veya “yüksek” öncesi VKİ’ye sahip olan bireyler, genellikle “düşük” veya “yüksek” bir sonraki (sonrası) ölçüme de sahip oluyorlar.
Sig. (p = 0,000)
Bu korelasyonun tesadüfen 0,920’den büyük bir değer alması pratikte imkânsız (p < .001).
Yani öncesi ve sonrası VKİ’ler gerçekten birbirine bağlı ve bu ilişki istatistiksel olarak anlamlı.
Neden Önemli?
Paired Samples T‑Test’te, ölçümler arası farklar test edilmeden önce bu iki ölçümün birbirine ne kadar “bağımlı” olduğunu bilmek faydalıdır.
Çok yüksek bir korelasyon (r > .80) bize, bireylerin kendi içlerinde tutarlı bir değişim yaşadıklarını, dolayısıyla ortalama fark testinin (t‑test) gücünün yüksek olduğunu işaret eder.
Özet:
Öncesi/Sonrası ölçümler birbirine çok benziyor (r = .92),
Bu bağlamda t‑testinin “bağımlı örneklemler” varsayımı tam da sağlanmış oluyor.
Tablo 3: Ortalama Farkın Testi (Paired Samples Test)
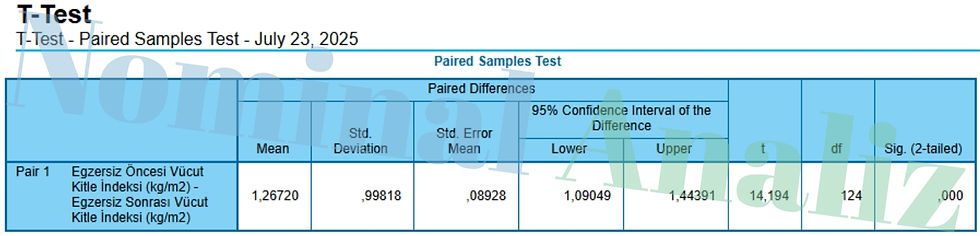
Mean (1,26720)
Egzersiz öncesi ve sonrası VKİ farklarının ortalaması ≈ 1,27 kg/m².
Yani katılımcıların ortalama VKİ’si egzersiz sonrası 1,27 puan düşmüş.
Std. Deviation (0,99818)
Farkların standart sapması ≈ 0,998.
Bireyler arasında ortalama fark ±1 civarında değişiyor.
Std. Error Mean (0,08928)
Ortalama farkın standart hatası ≈ 0,089.
Örneklemden elde edilen bu ortalama farkın, gerçek popülasyon ortalamasını ±0,089 belirsizlikle tahmin ettiğini gösterir.
95% Confidence Interval (1,09049 – 1,44391)
Gerçek ortalama farkın %95 güvenle 1,09 ile 1,44 arasında olduğu söylenebilir.
t = 14,194; df = 124
Test istatistiği oldukça büyük (|t|≫2), df = n – 1 = 124.
p < .001
p değeri çok küçük, farkın tesadüfi olma olasılığı pratiğe döndürülemez.
Yorum
Egzersiz programı katılımcıların VKİ’sinde ortalama 1,27 kg/m² anlamlı bir azalma yaratmıştır (t(124)=14,19, p<.001). %95 güven aralığı bu farkın 1,09–1,44 arasında olduğunu gösterir.
Bir sonraki adımda, bu farkın etki büyüklüğünü (eta², r² veya Cohen’s d) hesaplayarak “egzersizin” VKİ üzerindeki pratik önemini değerlendireceğiz.
1- Eta Kare (η²)
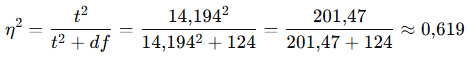
Toplam varyansın % 61,9’u egzersiz etkisiyle açıklanıyor (büyük etki).
2- Pearson’s r
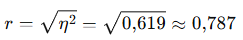
Öncesi‑sonrası VKİ’ler arasında güçlü bir ilişki (r≈0,79).
3- Cohen’s d
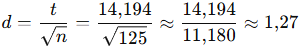
1,27’lik d değeri “çok büyük” etkiye işaret eder (d ≥ 0,8 büyük etki).
Yorum:
Egzersiz programı, katılımcıların VKİ’sinde hem istatistiksel (p<.001) hem de pratik açıdan çok büyük bir iyileşme sağlamıştır: ortalama 1,27 puan düşüş, varyansın yaklaşık % 62’sini açıklayan ve güçlü bir etki (r≈0,79) gösteren bir değişimdir.
Bu sonuçlar egzersizin VKİ üzerinde hem anlamlı hem de klinik/pratik olarak önemli bir etkisi olduğunu kanıtlamaktadır.
Aşağıdaki dosya indirme bağlantısından bu çalışmaya ait SPSS çıktısını güvenle indirebilir ve inceleyebilirsiniz.



Yorumlar